

We do a lot of data processing and management at Outlandish, and we decided to take Amazon’s new Machine Learning service for a spin with our partners The Audience Agency. We found that despite the hype around machine learning and what seemed like a great use case, it’s never going to be as simple as plugging ugly data into a system and getting useful insights out.
Machine learning generally refers to the use of computer modelling to detect patterns in data that can be used for generating predictions or other insights. It’s an alternative to manually building up logical data models and is useful when there is a large amount of data or too many different factors/dimensions to manually take account of. For example, Amazon’s shop has too many products for someone to manually tag them to say “people who bought this screen also bought this HDMI cable”. Instead, they use machine learning to look for patterns in transactions and generate automated suggestions.
The Audience Agency provide audience insights to the UK’s leading arts organisation through the Audience Finder platform that we’ve developed for them over the past four years. They have billions of data-points in about five years of box office and survey data which are used to generate insights and benchmarks that the arts organisations can use to hone their offering.
For our experiment we decided to attempt to predict the income for a show based on the time of the show, the type of performance and the organisation that hosted the event. The idea was that if we could create an accurate model we could help organisations work out when would be most profitable to put shows on.
The process involved:
- Creating queries that would export the Audience Finder data in a shape and format compatible with Amazon ML
- Load the data into ML from AWS S3
- Create a schema for the data that allows ML to interpret the data correctly
- Train the ML model to predict the likely income for a show based on the other factors
- Test the model to see if it is accurate enough to help with show planning
Create the queries
Audience Finder has tables of performances, transactions and organisations, so creating the data was just a question of joining the organisations and transactions to performances and then grouping the data by performance and date while generating a sum of the total income for each performance. Since these queries only needed to be run a few times performance was not a major issue, although we did end up using AWS Aurora’s new clone functionality to create a much larger database instance which cut query times from about an hour to under five minutes.


The new clone functionality allows you to create a new database in minutes which is great for scaling databases, prototyping and ad-hoc queries
Loading the data
AWS has made importing the data into ML incredibly easy. Simply upload a CSV to an S3 bucket, tell ML the name of the bucket, accept the permission prompts and you’re away.

Generating the schema
AWS makes your life a lot easier by guessing the schema for you. It makes the sort of mistakes you would expect from a computer – guessing that the performance ID and organisation IDs are numeric values rather than an identifier or categorical information. However, its very easy to put this right and (in our case) didn’t make too much difference to the model anyway.


Once you’ve defined the scheme you tell AWS ML which value you want it to learn to guess – in this case the total income for each show, as well as giving it a unique identifier for each record (in this case the perfomance_id).


Training the machine learning model – don’t forget to randomise the data
AWS by default uses 70% of your dataset to train the model. Essentially this means that AWS guesses some variables and tries to keep guessing the correct income for a range of shows. It automatically varies the variables in order to try to work out what relationship between the other (non-guessed) factors produces the most accurate results.
Our data was already sorted by income (the property we are trying to predict) so if the model is trained on the first 70% of data it will skew it towards certain types of performances. We therefore needed to use the custom options:


There are lots of advanced options for customising your data, but only the shuffling had a significant impact for us.


 Once you’ve configured that data source and model settings you can begin to train your model and evaluate you data. In our case creating and training the model on 160,000 records took around four minutes to complete
Once you’ve configured that data source and model settings you can begin to train your model and evaluate you data. In our case creating and training the model on 160,000 records took around four minutes to complete

Once we’d got the sorting and shuffling right AWS seemed pretty confident with the quality of our model:

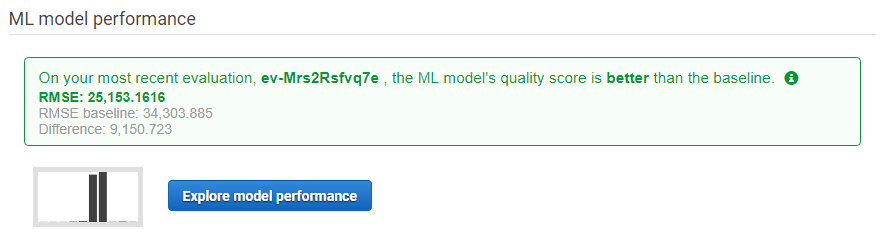
Unfortunately, that’s where the out of the box magic stopped for us. AWS provides an excellent evaluation tool that makes it really easy to test the model:


Unfortunately, try as we might we couldn’t get the predictions to be accurate. The main problem is that the model often predicts significant negative numbers which isn’t possible since we are trying to predict income from ticket sales, and no organisations sell tickets with negative value. It seems somewhat strange that a training set with no negative values would predict negative values in nearly half of cases, but when you think about how machine learning works it’s not that surprising. If we had more control over the training of the model we could fix this, but there’s no way (that we could find at least) to instruct AWS ML to use only positive values.
One reason for the inaccuracy of the model is the variability of the data, as our partners at The Audience Agency know only too well. There are free shows, for example, where all the tickets are given away to schools, community groups or other good causes. This means that a show which might otherwise be very profitable would have an income of £0 (or close to). This would obviously throw the model and cause it to (inaccurately) attribute the drop in income to factors such as day of the week or start time. The Audience Agency spend a long time (and deploy a great deal of expertise) in cleaning and normalising the data before they begin analysis – at least they’re not out of a job just yet.
Another way to improve the accuracy of the model would be to include more data. For example, we know where each organisation is based, which people attended which shows when, etc. – data that could be a goldmine for predictive modeling. The only issue is that this data is very relational – we know about households and performances and we need to understand the relationship between the two, so creating a simple regression prediction as AWS ML is setup to do is not easy. For these more complicated models something like TensorFlow, Gluon or SageMaker – all of which we look forward to trying in the not too distant.
Conclusion
The aim of our experiment was to find out whether simple ‘out of the box’ machine learning platforms could easily and quickly generate accurate predictions from an unprocessed dataset – the answer for our use case was no. It was easy and quick, but not accurate. We have a few other machine learning experiments coming up, so stay tuned. A lot of the current press about machine learning seems to suggest it is somewhat magic – it can drive cars and prevent heart attacks – it’s just important to remember that it’s only as good as the data it receives and the way the mode is trained, so there will be a place for human experts for a while to come.
[header image credit: Photo by Randall Bruder on Unsplash]



